
The Internet (or Net) is the logical network capable of interconnecting anyone with a computer and telephone via the TCP/IP communications protocols. Transmission Control Protocol (TCP) controls how packets of information are assembled and disassembled for transmission over the network. The Internet Protocol (IP) controls the address portions of the packets. The Internet is evolving into a global World 3 memory for the whole of humanity, with a level of complexity approaching that of biological nervous systems (Figure 15). The Internet supports several different kinds of communication and information interchange standards within TCP/IP: E–mail, gopher, File Transfer Protocol (FTP), Internet telephony, and the HyperText Transfer Protocol (HTTP). HTTP – which has completely supplanted gopher – forms the basis for the World Wide Web (or Web).
Figure 15. Internet interconnectivity between servers, hubs and trunks. Each color indicates the connections within a single country. – http://www.caida.org/ (from http://www.caida.org/outreach/presentations/Viz0002/).
All of these Internet features extend human capabilities to transfer and communicate knowledge artifacts, and are revolutionary by comparison to any previous communication technologies. The Web is the most revolutionary of all of these. The origins and evolution of the Internet and Web are well–documented152, and will not be reviewed except to highlight the origins of particularly significant features. I wish to focus on those capabilities of the Web that generate epistemic power: linking and hypertext; indexing, search and retrieval; and semantic and cognitive processes that are built into some of the more advanced “search” engines.
The original idea leading eventually to the development of the Web was proposed in 1945 by Vannevar Bush, Science Advisor to Franklin Roosevelt during World War II. In a discussion of the [even then] problems keeping track of proliferating scientific knowledge, Bush (1945) raised the idea of a desk–top associative memory aid based on microfilm technology to record logical connections or links between documents in the building of knowledge. He called this tool the “Memex”. The basic idea of the Memex is “...associative indexing... which is a provision whereby any item may be caused at will to select immediately and automatically another. This is the essential feature of the memex. The process of tying two items together is the important thing.”153 In this definition I would emphasize that selecting a linked object automatically retrieves it for viewing. For the scientific, technical and academic literature, reference citations and citation indexing provide this kind of linkage. The Memex was intended to provide this linkage in real time.
The terms hypertext and hypermedia were introduced by Ted Nelson154 (1965) at the 20th National Conference of the Association for Computing Machinery, with the first Hypertext Editing system developed by IBM for its 360 computers. The ideas continued to develop through the ‘70s and ‘80s155. One of the first personal computer implementations was Apple Computer’s HyperCard, which was introduced in 1987 (Feizabadi, 1998).
The World Wide Web concept, including a hypertext/hypermedia capability, began at CERN (European Organization for Nuclear Research) in 1989. Tim Berners–Lee proposed implementing hypertext linking technology specifically as an organizational knowledge management tool to keep track and record contextual connections among of the growing and evolving body of information assembled by the many scientists passing through the institution – which otherwise would be lost on their departure:
In providing a system for manipulating this sort of information, the hope would be to allow a pool of information to develop which could grow and evolve with the organisation and the projects it describes. For this to be possible, the method of storage must not place its own restraints on the information. This is why a "web" of notes with links (like references) between them is far more useful than a fixed hierarchical system. [my emphasis]
... We should work toward a universal linked information system, in which generality and portability are more important than fancy graphics techniques and complex extra facilities.
The aim would be to allow a place to be found for any information or reference which one felt was important, and a way of finding it afterwards. The result should be sufficiently attractive to use that it the information contained would grow past a critical threshold, so that the usefulness the scheme would in turn encourage its increased use.
The passing of this threshold [would be] accelerated by allowing large existing databases to be linked together and with new ones. (Berners–Lee, 1989–1990)
Rada (1991), in a seminal work156, explored the concept of hypertext in detail.
Ideas for the World Wide Web were first developed late in 1990 on a NeXT environment using object-oriented technology. The software was ported to other platforms. Berners–Lee released his WWW concept to the world in 1991 via the WWW–talk mailing list (Berners-Lee, 1999; Raggett, 1998) The concept included HTTP, HTML, Web servers and clients, and the idea of the Uniform Resource Locator (URL).
The URL is the named location of a file (resource) available for delivery over the Internet. With HTTP, the file can be an HTML page or any other type of file supported by HTTP (e.g., graphics, Java programs, etc.).
Once the WWW concepts and the protocols were placed in the public domain, programmers and software developers around the world began introducing their own modifications and improvements. Marc Andreesen was one such programmer. Andreesen, a graduate student at the University of Illinois' NCSA (National Center for Supercomputing Applications), led a team of graduate students (including Eric Bina) who, in February of 1993, released the first alpha version of his "Mosaic for X" point–and–click graphical browser for the Web implemented for UNIX. In August of 1993, Andreesen and his fellow programmers released free versions of their Mosaic for Macintosh and Windows operating systems. This was a significant event in the evolution of the world wide web in that, for the first time, a world wide web client, with a relatively consistent and easy to use point–and–click GUI (Graphical User Interface), was implemented on the three of the most popular operating systems available at the time [my emphasis]. By September of 1993, world wide web traffic constituted 1% of all traffic on the NSF [Internet] backbone. (Feizabadi, 1998: 1.3.1).
In 1994, the Mosaic team set up their own company and began developing the Netscape product. With Tim Berners-Lee's encouragement, the World Wide Web Consortium (W3C) was also formed in 1994 as an international body to provide a central steering and standards organization for the Web. This was followed by the release of Netscape's and Microsoft's browsers, which made information on the Web universally available to anyone with a personal computer and a modem, a standard telephone line and a desire to access it.
The Web is becoming a massive repository of all kinds of human knowledge. Tools for building, indexing and retrieving this knowledge include standards and several major groups of applications: structured authoring tools (SGML, HTML and XML), servers, browsers, indexing and search engines.
Standards
The development and use of standards for encoding, representing and transmitting content has been particularly important in the development of the Web, because it has made the creation and access of information independent of any particular proprietary software.
To now, the primary standards enabling the Web have been HTTP and HTML. HTTP enables the exchange of requests, Web pages, and the processing of hyperlinks in those Web pages. HTML provides a standard markup understood by Web browsers able to convey enough formatting information for a reader to apprehend document structure. Although the HTML language is defined by an SGML DTD, because HTML (like word processing markup) is almost exclusively concerned with encoding the visual formatting of the information retrieved, it conveys limited semantic information beyond the raw text. As will be explained below, XML is beginning to replace HTML as the preferred tool for Web authoring, because XML allows content to be tagged semantically.
Authoring tools
HTML was initially designed to provide a limited range of formatting and hyperlinking capabilities, and for its tags to be comparatively simple to type using nothing more than a text editor. However, as demand grew for including a wide range of graphic and formatting objects such as lists, tables, frames, dialog boxes, etc., HTML tagging became increasingly complex, and a number of authoring tools offering similar formatting capabilities to word processing were brought to market. Structured authoring/editing tools are applications specifically designed to help authors tag text and other content in SGML, HTML or XML. Word processors (e.g., MS Word) are also now being equipped with capabilities to save text as HTML. In January 2003, Yahoo listed more than 60 HTML editors157. XML's coding requirement are much more stringent than they are for HTML, and authors wishing to use XML markup for their texts will find that XML editors are essential. In January 2002, more than 45 editing tools are listed by XML.COM (in January 2003, more than 50 were listed)158. Several of these are directly based on the SGML editors summarized above; and some of the SGML/XML editors also have the capacity to save formatted text as HTML.
Web servers store, generate and retrieve content for delivery to the Web in response to HTTP requests. Depending on the volume of material delivered to the Web, the number of requests for information and requirements to generate information from databases, servers can range in size from a single PC in a home office to supercomputers or server farms containing hundreds or even thousands of PCs159. Servers may provide search engine and/or directory services.
Browsers are the primarily tools for viewing (but not editing) documents160. Web browsers are internet clients on end users' systems that communicate with Web servers via HTTP to retrieve content and display it for the human operator. In mid 2001, except for embedded graphics, the substantial majority of Web content retrieved is still presented in HTML. The latest versions of Netscape, Internet Explorer and Opera are including capabilities to understand XML190. In time, XML and its associated formatting standards allow the semantic structure of documents to be marked up for both semantic processing and for display in an easily comprehensible format for the human reader. Browsers offer capabilities for rendering or downloading documents in other file formats (either directly or via "plug-ins"), but these do not add significant epistemic quality to content in isolation from the other two classes of Web tools.
Retrieval tools
Given that tools exist to author Web content, link content to other content on the Web and to display content retrieved via Web links, the critical tools for recovering Web content of high relevancy are the Web catalogs (directories) and various kinds of Web search engines. These attempt to index the full content of the Web for easy human retrieval, and many are provided as free services to Web users.
All of these classes of tools are required to make the Web work as a practical respository for knowledge. However, the activities that provide the greatest value to facilitate the aggregation and retrieval of recorded knowledge are those of creating, describing and identifying links between documents. Even the average individual's home page, by providing links to other pages, provides additional semantic information based on the objective structure of the Web's World 3 to identify and qualify knowledge that can be retrieved by following these links – as foreseen by Vannevar Bush's Memex concept, citation indexing and demonstrated by the present hypertext document. Web links represent assimilated information. Russ Haynal (2000) explains how the pieces fit together into a complete architecture.
Because the Web (and the Internet which contains it) originated in the academic world and was highly subsidized by the US government162, major fractions of the knowledge being placed in the Web and the crucial storage and communications infrastructure for accessing this knowledge were freely available to end users163. Undoubtedly fuelled by the growing epistemic value of the content that can be retrieved essentially for free, the Internet's rate of growth was unprecedented in human history (Table 1, Figure 13), and it soon grew beyond anything that was economically capable of being supported by university or Defence Department hosts. Commercial organizations known as Internet Service Providers (ISPs) evolved to provide the host computers and telecommunications interconnectivity to tie the information resources and users together. Similarly to telephone exchanges, the highly automated ISP's are funded by people seeking hosts for knowledge they wish to place on the Web and by end–user subscriber charges. Many of those seeking services to host their content have something to sell, where hosting costs can be funded from profits. As will be seen, the result is a system that provides end users with access to a cognitively significant fraction of the world's textual knowledge for costs comparable to ordinary telephone services.
Table 1. Internet Growth (from Gromov 2002)
|
Date |
Hosts a |
Domains b |
WebSites |
WHR(%)c |
|
1969 |
4 |
|
|
|
|
Jul 81 |
210 |
|
|
|
|
Jul 89 |
130,000 |
3,900 |
– |
|
|
Jul 92 d |
992,000 |
16,300 |
50 |
0.005 |
|
Jul 93 |
1,776,000 |
26,000 |
150 |
0.01 |
|
Jul 94e |
3,212,000 |
46,000 |
3,000 |
0.1 |
|
Jul 95 |
6,642,000 |
120,000 |
25,000 |
0.4 |
|
Jul 96 |
12,881,000 |
488,000 |
300,000 |
2.3 |
|
Jul 97 |
19,540,000 |
1,301,000 |
1,200,000 |
6.2 |
|
Jan 98 |
29,670,000 |
2,500,000 |
2,450.000 |
8.3 |
|
Jul 98 |
36,739,000 |
4,300,000 |
4,270,000 |
12.o |
|
Jul 01 |
126,000,000 |
30,000,000 |
28,200,000 |
22.0 |
|
|
|
|
|
|
A host is a domain name having an IP address (A) record associated with it. This would be any computer system connected to the Internet (via full or part–time, direct or dialup connections). ie. nw.com, www.nw.com (http://www.isc.org/ds/defs.html)
A domain is a domain name that has name server (NS) records associated with it. In other words, there may be subdomains or hosts under it. ie. com, nw.com (commercial –– com.; non–profit organizations –– org.; educational ... ––– edu.; ... etc.). Domains are addressable by various Internet protocols. WebSites are specifically HTTP servers.
Web sites to Hosts Ratio – "very approximately (!) estimates the percent of content active part of Net community. By other words, WHR reflects what is the percent of Web surfing people that are trying to become the Web authors by creating their own Web sites.
First year of experiments with HTML and WWW architecture.
First year of the public Web.
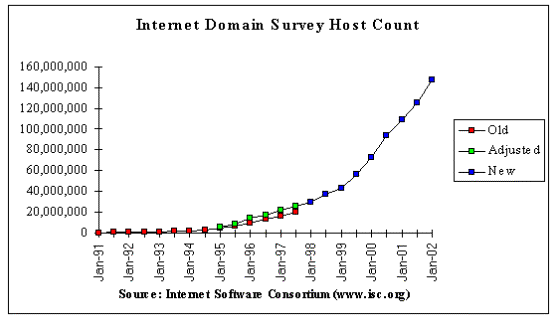
Figure 16. Growth in the Number of Internet Hosts164.
By January 2002, the number of hosts had grown to 147,344,723, from 72,400,000 in January, 2000165 (Figure 16). At the end of Q3 1999, Cyber Dialogue found that 69.3 million U.S. adults, or 35% of the adult population, were actively online. The total includes all adults who report that they "currently use" the Internet or an online service for personal, business, or academic purposes. The vast majority (90%) of adults who define themselves as "current and active" report going online at least weekly, with nearly all (97%) reporting that they go online at least once a month; while one third of the US population still claimed they have no need of the Internet166. Computer Industry Almanac Inc report that at the end of 2000, 114 million people in the U.S. used the internet every week (135 million overall), with total world usage being 300 million weekly users and 414 million overall167. NUA Internet Surveys, estimates that 605 million people world wide (183 million in the US and Canada – based on Nielson) were online in September, 2002168. The median guess for the "online shoping" revenue from the Web in 1999 was $US 19 billion (estimates listed by NUA ranged from 3.9 to 36 billion)169. The estimate for "internet generated revenue" in 2001 was $US 717 billion and $1,234 billion in 2002170!
NOIE report on iE-Service Capability & Online Activities has good stuff - http://www.noie.gov.au/projects/framework/Progress/ie_stats/CSOP_Dec2003/online
Although is is comparatively easy to count the number of computers hosting information for the Web, it more difficult to estimate that quantity of information available to the Web.
In January 2000, Inktomi, estimated that the Web contained more than one billion separate Web pages171. In July 2000, Cyberveillance counted two billion Web pages, averaging about 10 KB per page, with an estimated doubling time in the number of Web page of about 6 months (Murphy and Moore 2000). On June 26, 2000, Google announced that their search engine had actually identified over one billion Web pages172. By December 2001 Google claims direct access to more than two billion (HTML) Web pages and more than three billion documents overall. In November 2002, Google claims more than three billion Web pages and four billion documents (Notess 2002b). Although these are simple quantitative measures, given the size of the numbers it is difficult to know exactly what has been counted (Notess 2002a; Sullivan 2000). According to Lyman and Varian’s (2000) survey of surveys, in mid 2000, the Web contained some 10–20 terabytes of readily measurable information (i.e., text)173.
There is a much larger volume of information available via restricted portals to various kinds of static or dynamically generated pages and databases not available to the normal Web indexing services. For example, the arXiv.org e–Print archive server provides free access to preprints in physics and related disciplines. As at January 2003 the server held more than 220,000 articles, but has site policies that exclude Web crawlers174. As at January 2003, Elsevier's Science Direct provides subscription only access to the full content of more than 3,000,000 articles in more than 1,700 journals plus 59,000,000 abstracts from all fields of science175. This larger volume of content not available to the normal Web indexing systems has been variously termed "deep content" or the "invisible Web" (Bergman 2000; Sullivan 2000a). Bergman estimates that the invisible Web contains at least 500 times the content covered by the normal indexing systems. Taking Bergman's and other estimates of the size of invisible Web, Lyman and Varian (2000) estimated the invisible Web to contain around 4,200 terabytes of high quality information176. Some of this invisible content is available for free. Some, including the content of most academic, technical and professional journals, is only available via costly institutional or individual subscriptions177.
As an aside, it is also interesting that the How Much Information study estimates that there were 500 to 600 billion e–mail messages generated in 2000, taking up approximately 900 terabytes of storage at any one time (much e–mail is not saved)178.